6。 浏览网站图片
如果你想浏览某个网站的全部图片,可以在 Google Images(
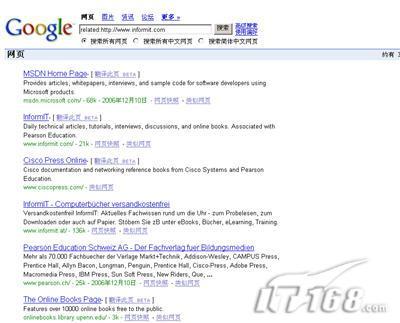
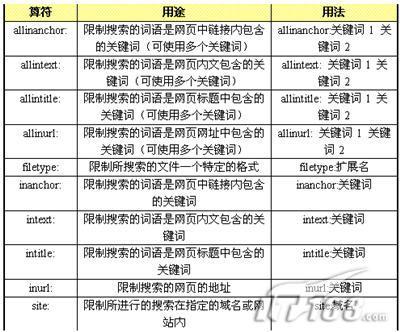
http://images.google.com )的”site :”操作符也许你已经在Google 的网页搜索中知道了这个操作符。例如,在Google 图像搜索框内键入site:cnn.Com 则可以看到CNN 网站内的全部图片。点击搜索结果中的某张图片,你就可以进入该图片所在的页面。
当你只是想查看某个网站的图片或者你对该网站的实际文字内容不感兴趣的话,这无疑是个有趣的方法。同样的,你仍可以在搜索中加上关键字。使用关键字:site:cnn.com clinton 就可以得到CNN 上克林顿总统的或与之相关的图片。
想要在一个比 CNN有趣些的网站上试试这个功能么?我向你推荐用如下关键字进行搜索: site:worth100.com,则你将会看到数以千计的精彩图片。
7。Google运动简史
也许所有的运动都是愚蠢的,其实人类也会是。 ――罗伯特 ·林德
人们如今经常参与到一项名为” 搜索引擎优化竞赛” 的挑战中。简言之,这类竞赛的目的就是使某种给定的短语或句子在Google 搜索中的页面排名最高。为了不影响正常单词的搜索结果,竞赛一般都选择生僻的单词作为目标关键字。起初,我会经常参加这类竞赛,在经历了多次以后(包括有一次的关键字是” Seraphim Proudleduck “)我不再热衷于此。在我们回顾搜索引擎优化竞赛历史之前,我们先回到几千年前,从搜索引擎本身的历史开始。
公元前- 1956年 计算机业的黎明
在公元前就有了一种协助计算的工具-算盘。直到 1642年, 柏莱斯·帕斯卡发明了第一台机械计算器。到了 1820年, Charles Babbage发明了蒸汽动力差分机,拉夫拉斯伯爵夫人拜仁与他相遇后就开始考虑差分机的可编程性。
第一台计算机(可编程计算器)由德国工程师 Konrad Zuse与 1941 年完成。
英美两国主导了计算机领域的技术,随后便出现了 Colossus, ENIAC ,晶体管计算机(贝尔电话公司),通用自动计算机。
1957-1990 互联网
为促进美国科技发展, ARPA(美国国防部高级研究计划署)与 1957年设立。约十年后, DARPA成为了互联网的开端。 Intel公司于 1968年成立。 Doug Engelbart展示了他那具有革命意义的关于文字处理的想法,一年之后,施乐创立了具有同样革命性意义的 PARC,帕洛阿尔托研究中心。 1969年,各大院校逐步开始通过 ARPANET连接起来。 1977年,苹果 II型电脑诞生,随后 IBM个人电脑也于 1981年上市。 1984年是属于电脑朋克小说《神经漫游者的一年》,文中首次出现了 DNS域名解析系统的概念。
八十年代后期,英特网上的主机数量突破了100,000台,网民开始感觉迷失。1990年,在万维网出现之前,Mc Gill大学的学生Alan Emtage编写了FTP索引搜索工具Archie;一年之后,Mark McCahill编写除了它的替换者Gopher。Veronica(漫画书中Archie的女朋友,被戏称为搜索引擎的祖母)接着在1992年出现,它能够索引并检索Gopher空间上的目录信息;Jughead于1993年问世。
1990-1993: WWW, 和WWWW
同时,在1991年,由Tim Berners-Lee发明,经CERN(the European Organization for Nuclear Research,欧洲核子研究中心)发布的全球资讯网(the World Wide Web)面世。1993年,第一个浏览器Mosaic的出现震撼了全球;同时,Mattew Gray开发的第一个网络机器人——网络漫游者(World Wide Web Wanderer)问世。
1994: 搜索引擎曙光出现
全球资讯网逐渐成为最重要的一项英特网服务,人们可以在线定购比萨。同时Sun公司随即开发出了Java编程技术(Java的宗旨是“一次编写,随处运行(write once, run everywhere)”,但是世界各处受到挫折的程序员们不久后将其改成“一次编写,随处调试(write once, debug everywhere)”。)
1994年初,斯坦福大学的杨致远(Jerry Yang)和David Filo创立了雅虎,目的是运用各种命令来处理无政府主义的文件。雅虎是“Yet Another Hierarchical Officious Oracle”的缩写,意为“另一个层次化的、非正式的预言”,看上去似乎可能是两位雅虎的创始人在字典里面随机挑选出来的,不过两位创始人宣称它们喜欢这个名字是因为它们认为自己就是雅虎s。
几个月后,Brian Pinkerton开发的WebCrawler搜索引擎在华盛顿开始运行;同时在卡内基梅隆大学,Michael Maldin 博士发明了Lycos搜索引擎(名字取自拉丁文:狼蜘蛛)。
1995-1997: .Com热潮
越来越多的搜索引擎出现了。比如说Metacraler、Excite(1995年末)、AltaVista (1995年末)、Inktomi/ HotBot (1996年中期)、Ask Jeeves以及GoTo。雅虎是当时的业界领袖,但它实际上是一个目录;于1995年创立的AltaVista(意为“鸟瞰”,同时也是一个双关语“展望Palo Alto研究中心”)带来了激烈的竞争。1997年,AltaVista由康柏(Compaq)公司收购,我们可以假设这直接导致了它失去重心,继而没落。
1998-2002: Google们
1998年末,来自斯坦福大学的Larry Page和Sergey Brin在论文“大规模超文本网络搜索引擎解析”中重新研究开发了搜索排序技术,随后,这成为了世界上最为成功的搜索引擎:Google。这是Larry将Googol一词错误拼写的结果,Googol的真正含义是大量的数字;同时Sergey使用免费的GIMP绘图软件亲自设计了Googel的彩色LOGO。整洁的界面,速度以及搜索结果准确度是赢得精通技术者好感的基石,而正是这些人引导了大多数网民在网络上的行为。其它竞争者,比如MSN,被甩在背后的尘埃后。1999年9月份,Google结束试运行。
同时,搜索引擎优化成为了一项越来越受关注的活动,专家和业余爱好者都希望能头提高网站在搜索引擎中的排名,而这样的活动动机通常都是非商业的。
2000年,雅虎和Google成为合作伙伴(雅虎在自己的网站上使用了一段时间Google的搜索技术)。2000年末,Google每天平均接收到超过100,000,000条搜索请求。
2001年,AskJeeves收购了Teoma,同时更名为Ask;GoTo也将名字改成Overture。
2003至今: 搜索引擎竞争的开端
很难说第一次真正的搜索引擎竞赛是什么,自从搜索引擎诞生以来,人们就开始为了某些商业目的开始竞相争取搜索引擎的头条位置,这样的手段被称为搜索引擎优化。而所谓的SEO竞赛只是为了寻找乐趣,同时对Google神秘的排序方式进行探索——潜在的目的是为了利用这些排序方式。在竞赛中,时常也会有一些奖励措施。(提醒一下,这并不是全部——因为它只是一项在偏僻角落里的趣味运动而已。)
现在,这里有无数同时进行的不同的SEO竞赛,很难记录下全部。下面,我把最初我曾亲自在博客上参与过的SEO竞赛描述一下。
2004: SERPs
SERPs是搜索引擎结果页(Search Engine Result Pages)的缩写,非常巧的是,它同时也是“与收入关联国家养老金”(State Earnings-Related Pension Scheme)的缩写,这是针对关键字的搜索引擎优化竞赛。2004年1月16日,包括我在内的一群人在一个搜索引擎讨论组里面开始了这次名为SERPs的挑战。非常有意思的是,SERPs同时还有自我参考(self-referential)的含义,而且这个词可以认为是无害的——大概没有几个人会去搜索它吧。竞赛伊始,使用SERPs进行搜索能够得到30,700张网页,听起来似乎很多,但是这只是搜索“激动的演讲者手册领域”得到的页面总量的十分之一。
我在博客上发表了一篇文章,开始了这次竞赛,想看看它将在本次竞赛中如何进展(很快的,就跌出了前十名)。Google的博客社区Blogsopt的用户Sam在2004年2月16日取得了本次竞赛的胜利,他的策略是通过一种可以被视为散布垃圾广告消息的行为,在很多网站留言薄里面加上自己页面的链接。不过Sam已经注销了自己的博客,所以现在我可以开设一个和他同名的博客,从而登上搜索结果头条。
科巴普各兹(Kebapgraz)
“科巴普各兹”SEO竞赛的名字源自土耳其的一道菜名“Döner Kebap”,这道菜目前在德国和奥地利格拉茨市相当流行。本次挑战的参与者大多数也是来自德国和奥地利,在德语网页范围内进行。作为之前的“哈特兹莫桑根”(Haltezeitmessungen)竞赛的延续,本次挑战于2004年6月16日开始。通过与多个网站互链来提高排名的链接农场式做法,或者其它的一些散布垃圾广告消息的行为在本次竞赛中是不允许的。2004年9月10日,本次竞赛结束之时,通过Google搜索“科巴普各兹”得到的网页总数从0张增加到了167,000张。一个德国的wiki网站(wiki是所有人都可以参与编辑的类似于百科全书的一种网站)在竞赛过程中的大多数时候都占据了搜索结果头条的位置,只是在结束前的24小时被挤到了第二位。
本次竞赛是由一名来自奥地利的17岁少年David Reisner发起的,“有一天我突然想到,现在有很多有趣的竞赛在举行,但是网上却没有关于科巴普的信息。”David说。我问他从这次竞赛中学习到了什么东西,他答道一个人应该事先认识清楚竞赛的规则,以免日后像他那样与别人发生长期的冲突。他还提到,“在SEO竞赛中,这里有一个小窍门:先奉献,你将会得到回报;还有一个建议:多链接”。
斯克尼特兹米特卡特欧佛萨拉(Schnitzelmitkartoffelsalat)和 格帕登弗日伦(Gepardenforellen)
另外一个德语Google竞赛针对关键词“斯克尼特兹米特卡特欧佛萨拉”(Schnitzelmitkartoffelsalat),它的意思是配土豆沙拉的牛排。它由Steffi Abel与2002年10月15日在一个德语讨论组启动,那时,在Google搜索“斯克尼特兹米特卡特欧佛萨拉”得不到任何页面;三年以后,能够搜索到22,000个页面。德国站长Lars Kasper利用他的网站参与了本次活动,他说,“斯克尼特兹米特卡特欧佛萨拉”搜索结果的变化和“特勒弗得辛非兹尔斯杜迪”(针对保护电话安全的研究)以及“沃尔尼其特费斯克米特卡特欧弗萨拉”(配土豆沙拉的鲸鱼)的变化是同步的。
不久之后,德国的Google运动开始因为竞赛“胡明希·格帕登弗日伦”的出现而火爆起来。它由德国最大的IT杂志《上下线》发起,如今这两个关键词可以返回多达3,000,000张网页。
曼吉尔·德•斯佳吉内(Mangeur de Cigogne)
不久后,一个针对关键词“曼吉尔•德•斯佳吉内”的法国Google运动由Promo-Web启动,活动从2004年3月开始,至2004年6月15日结束,这可能是所有搜索引擎优化竞赛中最古怪的和最使人着迷的其中之一了。整个竞赛的内容全部由法语呈现,若你对这种语言不熟悉的话是很难搞清楚到底都发生了些什么的。
“曼吉尔•德•斯佳吉内”到底是什么意思呢?逐字翻译出来意为吃鹳的人。但是在来自法国南部的Jerome Chesnot看来,“它什么也不是,选择这个短语只是为了不影响Google的其它搜索结果而已”。
Jerome在比赛的最后15天一直保持着第一的位置,但是最后掉到了第二位。他说就HTML优化和其它技术方面的工作来看,参加“曼吉尔•德•斯佳吉内”竞赛真的是一次宝贵的经历。
深蓝(Nigritude Ultramarine)
“Nigritude Ultramarine”可以认为是至今最大的一次SEO竞赛,从Wired.com到科技站点Slashdot,都有它相关的文章,拥有极高覆盖率。本次竞赛由SEO公司DarkBlue发动,值得一提的是,“Nigritude Ultramarine”是深蓝的另一种说法。
Anil Dash的博客以微弱优势在2004年6月7日赢得了第一轮的比赛,第二名的奖品是17英寸的LCD纯平荧幕,由一个挑衅的竞争者——某网络论坛夺走。Anil的页面得到了很多来自其它优秀博客的链接,他们都想将自己的朋友送上第一的位置。Anil试图证明比起那些低级的优化策略,优秀的内容才是至关重要的,他成功的证明了这一点!
当我写下这些的时候,这里大概能搜索到296,000张网页包含了关键词“Nigritude Ultramarine”,而Anil Dash仍然处于第一的位置。
简明SEO指南
如何才能在搜索引擎优化竞赛中取得第一名呢?这与搜索引擎有关,但是对于Google来说,在页面上做过多的优化在竞争环境中是无意义的,重要的是看你做了多少页面内容以外的优化。
做一下解释,页面上的优化指的是你在某个页面的不同地方(如在META标签中,在页面标题里,在页面题目里等等)多次重复同一关键词。在页面上进行这样的行为可能会对你的人类读者造成影响——这也是很重要的——但是对于Google机器人来说却是没有什么价值的,Google感兴趣的只是有多少重要的页面链接到了你的网页并且使用了关键词作为链接文本。
如果你能够从权威网站(比如主流的新闻网,或者在某各领域排名第一的博客)获得大量有价值的回链,那么自然就能得到较高的排名。因此,真正的关键是取得好的回链(理想的链接包含目标关键字),并不需要有无数的回链,只要有10左右的高价值链接,附加上较多的普通回链就足够了。例如,Google一般都会忽略你从自己的网站A创建的100,000个到自己的网站B的回链(使用服务器端编程方法来创建这样大规模的链接并不是一件难事)。Google明白这样紧密结合的两个网站并不能表明自然状态下的权威——它们能轻易的被所谓垃圾广告消息散布农场伪造出来, Google在进行页面排序中避免的一个因素正是散布垃圾广告消息这样的形式。
那么如何从他人那里得到链接呢?现在,让我们暂时忘掉技术手段的优化。目前最重要的是拥有丰富的网页内容,并且使之被关键的人所获知——不是给所有人甚至它们的宠物都发送电子邮件的形式,而是通过在特定主题内提交你的链接、给关键的人发送电子邮件、向主流新闻网站推荐你的文章、在与你网站内容相关的讨论组或者论坛共享这篇文章等形式。在SEO竞赛之外,意味着你需要理解一个群体,成为此群体的一部分,然后帮助他人。人们不会与无聊的或者优化过度的网页交换链接,但是人们会与那些能够帮助他们或者使他们发笑的网页进行链接。一般人都会链接一份说明书、一篇优秀的文章、一段有趣的视频、一集卡通或者一些有意思的照片。在SEO竞赛的情况下,人们也有可能只是简单的与朋友链接。如果你在积极的尝试将网络变成一个对大家来说更好的地方(内容为王!),与大家分享你的“链接之爱”吧!

购买难易程度: